Unsafe Foods: Text Wrangling and Topic Modeling
Think back to the last time you wrote an online review. If you prioritized your spelling, grammar and formatting, the Unsafe Foods team would like to personally thank you. This past week, our team initiated work on several items, including the tedious task of cleaning Amazon review text data for preliminary analysis. Compared to other sources of text, which generally endure a rigorous editing and review process (e.g., newspaper articles), the unregulated world of online text presents Data Scientists with obvious cleaning and analysis challenges. However, the quantity and relatively easy access to online text data makes it a great source for projects that aim to analyze issues facing the general population (including our project!).
Previous work that mined text data from online restaurant reviews for the early identification of food-borne illnesses used specific keywords associated with reporting a food-related sickness (e.g., ‘sick’, ‘vomit’, ‘abdominal pain’, use your imagination….). However, these keywords may not be as applicable for food products. For example, if you review a restaurant based on a single experience, odds are you will only use the term ‘sick’ if you left the restaurant with one of the symptoms listed above. In the case of food products, we are dealing with some items that could potentially be used by consumers to alleviate gastrointestinal symptoms, like indigestion (e.g., seltzer water). Therefore, for an initial inspection of the review text data, the Unsafe Foods team employed methods of topic modeling, specifically Non-negative Matrix Factorization (NMF) and latent Dirichlet allocation (LDA), to get an idea of the broad types of categories Amazon grocery reviewers are discussing.
Topic modeling, at its simplest, is a way of determining the hidden categories that are present in a corpus of text. If you were given all the text from a newspaper, for example, topic modeling could be used to identify the general topics used to group individual articles (e.g., politics, sports, business) and the keywords that place them in these categories (e.g., ‘economy, vote, ballot’, ‘score, game, championship’….). This process is done by humans automatically - you can easily identify the type of article you are reading based on keywords and context. However, we can also do this mathematically, which can establish unobservable categories that are less obvious to the human reader.
NMF
Non-negative Matrix Factorization, or NMF, is one method for topic modeling. NMF is an unsupervised, linear-algebra based algorithm that performs dimensionality reduction and clustering simultaneously. The input for the algorithm is a document-term matrix, where each row, in our case, is a review, and each column is a term used in the grocery review corpus. Below is a visual of a document-term matrix from Derek Greene’s great introduction article on NMF. Higher frequency of a term is denoted by a darker shade of blue.
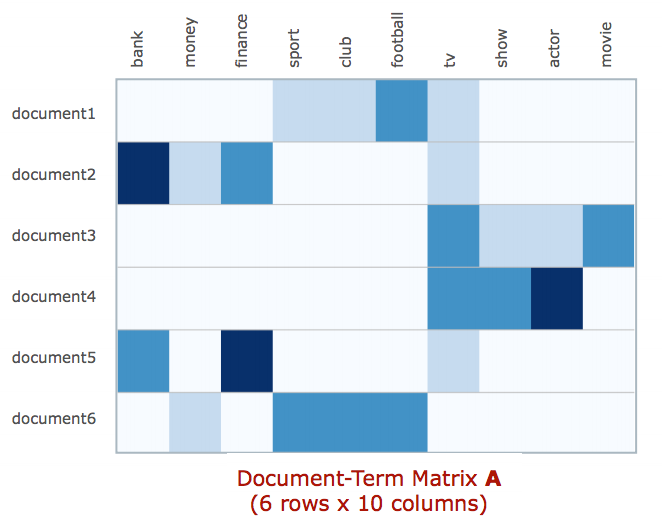
In order to create the document-term frequency matrix, some standardization of text is required. Specifically, we removed all English language ‘stopwords’ (e.g., and, the, has) which hold little value for modeling given their high frequency in all articles,removed special characters, made all text lowercase, stemmed each word to its root (e.g., running = run) and weighted term frequency using TF-IDF weighting, which lowers the weight of a term in the matrix if it is relatively common throughout the corpus.
The resulting matrix can be processed through various packages, including the Nimfa package in Python. NMF factors the document-term matrix into two matrices; a W matrix, which provides weights for the reviews relative to each identified topic, and an H matrix, which provides weights for the terms in the corpus relative to the topics.
The NMF process revealed some interesting ‘unobserved’ topics among the recalled products, such as one topic which hinted at the spoilage of products shortly after they were received (e.g., rancid, temperature, ruin).
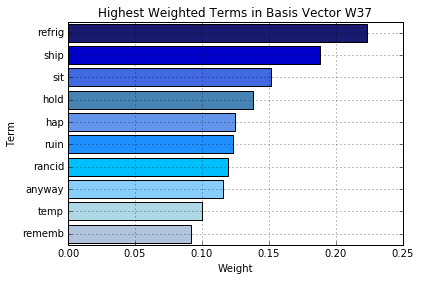
LDA
Latent Dirichlet Allocation, or LDA, has similar outcomes as NMF (e.g., topics and keywords) but uses a slightly different approach. LDA is a probabilistic model which assumes that each document in a corpus is a mixture of a small number of topics, with the topic distribution among the corpus having a Dirichlet prior. There are great visualization packages for LDA analysis, including LDAvis, which produced the topic graphic below for our review data:
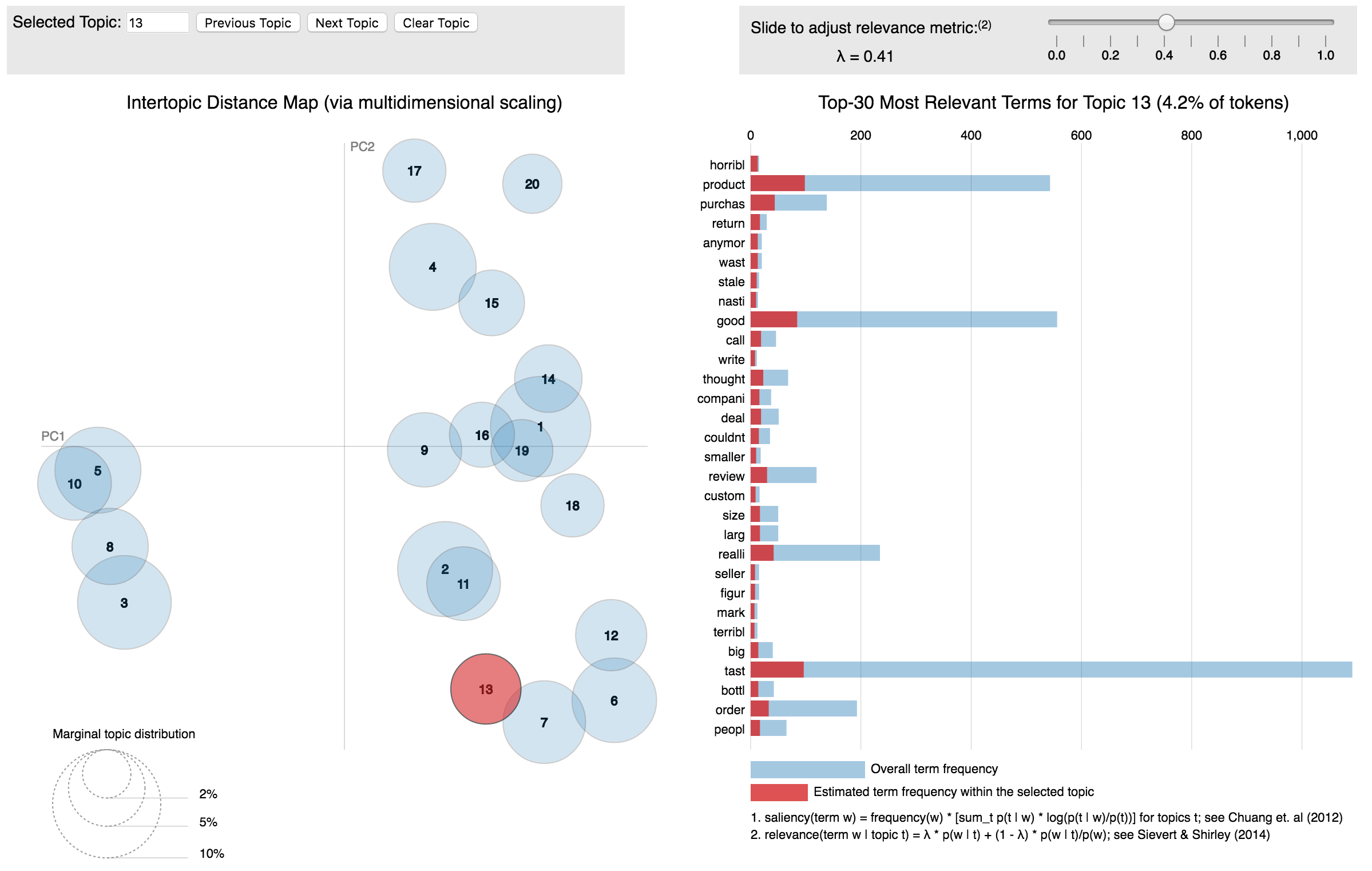
We’ll be playing with these models and expanding them over the next few weeks - more updates to come! Until then, please continue to use spellcheck when writing online reviews….