Unsafe Foods: Getting Information About Types of Recalls
In Text Mining, the simplest approach to classifying documents is by word count. This is often really useful when you’re dealing with corpora that have dry, defined subject matter. For more personal, less professional, shorter and to-the-point documents, such as social media posts or, in our case, reviews, this approach can sometimes be sub-par depending on how you are trying to classify your data. For the reviews, as we have seen in previous weeks from the results of topic modeling, we have learned that the overlapping language in the reviews more often concerns the type of product than it does the product’s quality. This causes the model to classify any reviews referring to products similar to recalled products in the training set to to be tagged as indicating that the product should be recalled. In other words, the word counts can over-fit our results based on the type of product.
So how do we approach this problem and account for it in our classification model? There are innumerable approaches, and this is a field that is still being researched. However, we have been investigating different ways to deal with our data set’s peculiarities this summer. One possible solution that I have been investigating is including the type of recall in our training data to see if there are any parallels in type of recall and type of negative review. For example, if one review is complaining about mislabelling, this type of vocabulary would be very different from one that speaks to foodborne illnesses.
In the FDA recall enforcement data, we have a field called ‘Reason for Recall’. Rather than a set of 5 or so different types of recalls, this part of the data is just a text field with no set format. Therefore, to extract types of recalls, we need to somehow extract topics or themes from the reasons for recall. For this exercise, I wanted to answer two questions: how many reasons for recall should be extracted from this data, and what recalls are assigned to each type?
The first hurdle was removing vocabulary that would throw off the topic model. We noticed that there were many proper nouns such as locations and brand names that were causing the poor formation of topics. To fix this, we decided to use Python’s NLTK package to tag the words in each reason for recall ‘document’. If it was tagged as a proper noun, we could then remove it in the preprocessing portion of the task. Unfortunately, many very important words were also proper nouns, such as bacteria, diseases, and unreported chemicals.
To handle this problem, we decided to try using Python’s Wikipedia module by attempting to identify categories of each term. If the term’s categories contained words within our list of key category terms, ‘disease’, ‘epidemiology’, ‘bacteria’, ‘preservative’, ‘refrigerant’, ‘food’, ‘edible’, ‘plant’, or ‘chemical’ (this could probably be further refined), then we left the proper noun in the token set. Otherwise, it would be removed. This proved to clean up our tokens pretty nicely.
This next step was answering the first question- how many topics should be generated from the topic model? For this, we performed a Stability Analysis using the K-Means clustering algorithm and then calculating the stability score1- that is, we compared the similarity of all unique pairs of clusterings generated at each number of topics within a given range (in our case 2 to 25). A high stability score indicates that the selected number of clusters provides consistent results on data coming from the same source. The stability score versus number of clusters for this data is visualized below:
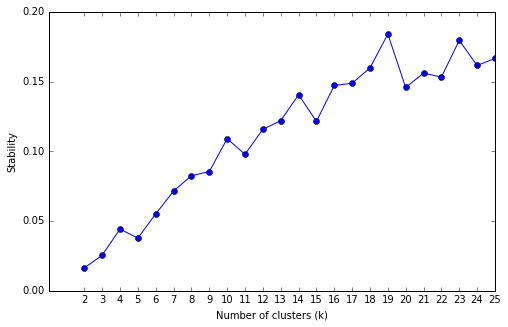
From the visualization, we see that there is a peak in stability at k = 19, so for our clustering algorithm we input 19 as the number of topics to output. We use Non-negative Matrix Factorization for our clustering algorithm. The top terms in each cluster were as seen below:
Topic 0: eld, infect, weak, immun, fat, sometim, frail, young, childr, system
Topic 1: rend, whereby, held, insanit, injury, becom, condit, prep, heal, fil
Topic 2: threatening, run, sensit, people, allergy, lif, risk, react, sery, sev
Topic 3: whole, foods, sold, amp, annount, depart, stor, item, these, chees
Topic 4: ingredy, decl, allerg, stat, milk, soy, label, list, whe, fail
Topic 5: smok, vacu, toxin, control, form, hot, grow, botulin, inadequ, salmon
Topic 6: film, chok, thin, slic, remov, hazard, wrap, stick, plast, could
Topic 7: tun, chunk, can, ount, wat, limit, equip, amount, undercook, routin
Topic 8: analys, sampl, bas, found, ppm, lab, priv, sulfit, rev, level
Topic 9: plac, correct, individ, box, bottl, bar, out, wrap, pack, unit
Topic 10: chloramphenicol, suppl, diet, dietary, enzym, antibiot, raw, supplements, mat, trac
Topic 11: blist, complaint, miss, inform, investig, packet, back, insid, carton, receiv
Topic 12: gram, panel, fact, serv, sug, per, nutrit, mg, tablet, sid
Topic 13: recal, contamin, pot, volunt, mango, due, peanut, sint, abund, caut
Topic 14: standard, meet, salt, tast, qual, ph, od, smel, yeast, coliform
Topic 15: screen, frag, faul, mesh, stainless, met, steel, flo, wir, party
Topic 16: see, chip, ad, sunflow, fruit, chocol, inadvert, dri, dress, kit
Topic 17: posit, test, second, custom, ship, receiv, not, on, salmonella, result
Topic 18: fre, grocers, unified, dairy, ind, glut, bakery, howev, claim, canadian
As you can see, some of these topics are identifiable to the human eye. For example, Topic 1 indicates a threat to vulnerable individuals, and Topic 4 indicates ingredients that can cause allergic reactions; this could indicate mislabelling.
From these results, we extracted the topic-term matrix and the reason-for-recall document-topic matrix. This data will be used to determine whether it can improve upon our classification model.
How Many Topics? Stability Analysis for Topic Models, Derek Greene