Upload Data, Get Answers, Share Results.
SQLShare is a database service aimed at removing the obstacles to using relational databases: installation, configuration, schema design, tuning, data ingest, and even application design. You simply upload your data and immediately start querying it.
How do you query your data? With a query language! Unlike most programming languages, a query language is declarative, meaning that the you describe only the result they want, not the exact procedure for how to obtain it. That procedure is decided by the database, which has access to information that you do not: where the data is physically stored, how it is physically organized, what kind of computational resources are available, even statistics on the data itself.
The Structured Query Language (SQL) is the most popular language for accessing and manipulating tabular data. The SQL database market is $18 billion per year, and the technology powers most of the web pages you visit on the Internet. Most importantly, though, SQL keeps easy things easy and makes hard things possible.
Say I want to find all the employees with a first name of “Bill,” I could write:
SELECT * FROM employees WHERE firstname = 'Bill'
That’s it. No need to locate a file on your PC, open it, etc. All that is handled transparently by the database.
Now I want to find all the proteins that are not expressed in at least one of three samples. The set-oriented nature of SQL and the relational data model make this query natural to express: simply construct the union of all three samples, then remove the intersection of all three. The result is those items that appear in at least one sample but do not appear in all three samples:
SELECT * FROM sample1
UNION
SELECT * FROM sample2
UNION
SELECT * FROM sample3
EXCEPT
SELECT * FROM sample1
INTERSECTION
SELECT * FROM sample2
INTERSECTION
SELECT * FROM sample3
Try that in a procedural programming language!
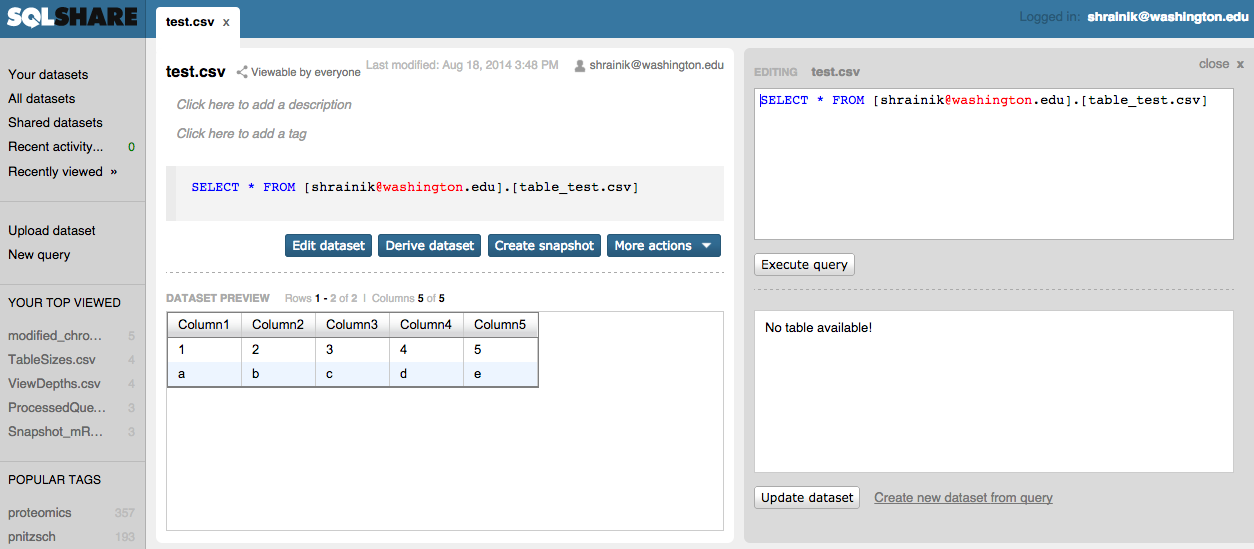
SQLShare in action, screenshot.
The left sidebar of the SQLShare user interface contains the dataset palette. Note that in SQLShare, “dataset” refers to an SQL query, title, description, and output. This is where you access your previously saved datasets, view your recent activity, and create new queries. When you select a dataset, a new dataset tab opens and displays the dataset definition, an English description of what the dataset contains, and a preview of the dataset’s results appear (at center). At the right is a workspace for creating a new dataset from an existing dataset.
We find that users frequently copy and paste snippets from other queries – a predicate, a column expression, a subquery – and paste them together to construct a new query. This workspace affords browsing and editing on the same screen.
This work is funded by the Gordon and Betty Moore foundation, NSF Award 1064505 “Database-As-A-Service for Long Tail Science”, and the University of Washington eScience Institute.