Data Processing
Using the Data
The FDA and Amazon datasets that were used in this project were semi-structured and had no immediate way to join them. Moreover, it required several cleaning tasks before it could be utilized in any way in a machine learning model.
The first task was matching the Universal Product Codes (UPCs) from the FDA data to the Amazon Standard Identification Numbers (ASINs) in the Amazon data. This was no simple feat, and it required a lot of creativity in scraping, checking, cleaning, and translating these codes. All of our work has been organized into processed UPCs and ASINs joined to recalls, reusable Python libraries with the flexibility to employ in other projects that are working with these product codes, and Jupyter Notebooks to walk users through our work. This can be found in our Github repository.
As seen on our Data Organizing page, this has all been cleaned and stored in a structured database. However, since the database is not publicly available, we have also provided information and code on how to work with the two datasets as they are in their original downloadable format in a Jupyter Notebook.
Tagging the Reviews
In order to develop a classification model, the objects that we are attempting to classify must be assigned tags. In our case, the tags would reference where or not the product review was published within the chronological vicinity of the time that an FDA recall corresponding to the product was released. This is not a very straightforward task, because the time frame between a product needing to be recalled and a product actually being recalled varies greatly. Since it is unclear the best way to define the recall/review relationship (should a review be within 1 year of a recall in order to provide accurate information? 6 months?), we defined four versions of the recall/review relationship:
-
Review is within (+/-) 1 year of the recall date
-
Review is within (+/-) 6 months of the recall date
-
Review is at most 1 year before the recall date
-
Review is at most 6 months before the recall date
In this way, we developed supervised models based on the four different tagging methods and compared.
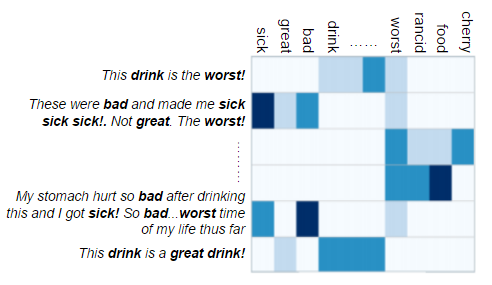
Cleaning the Text Data (Text Preprocessing)
Before we can perform any kind of analysis on the text, it requires reformatting in order to optimize our model. In cleaning the text, our goal was to modify the text enough to capture interesting features, while also ensuring that important but infrequent terms were not removed. The following steps were most common in our text preprocessing methods:
- Remove numbers and special characters.
- Tokenize the text (split it into individual words).
- Split unqualified compound words where found (CamelCase).
- Make all lowercase.
- Stem the tokens (cut them down to their root to maximize the intersection of related terms).
- Create a document term matrix (DTM) from the term frequencies.
- Perform TF-IDF weighting on the DTM. Since these texts are short, we also attempted developing models without TF-IDF weighting, as this method is ideal for texts longer than those found in corpora composed of texts like social media data.