Summary
Data
SSS Data
The Self-Sufficiency Standard data includes 147 files in Excel file format (xlsx, xlsb) by state and year. Each file lists counties with family types and related costs, such as housing, child care, and food costs. Most columns are consistent across files, but a few columns that contain extra information are present in specific files. For example, broadband and cell phone costs are only included in 6 files.
Additional Datasets
Data Preparation
To store data from all the files in a single database, we pre-processed the files to standardize the column names. We utilized Python packages such as Pandas and NumPy to read the data from the Excel files and to conduct data cleaning.
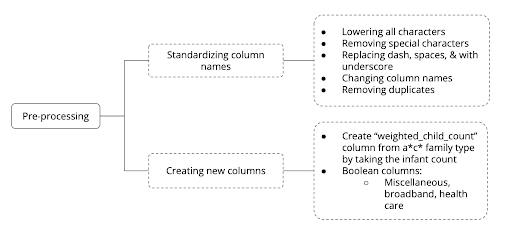
Figure 1: Pre-processing of the Self-Sufficiency Database
Tools
We used Python to read and clean the Excel files. Specifically, we used Pandas to read the files as data frames. We then implemented the SQLAlchemy library to create tables that are hosted in SQLite. To ensure we could insert information into the database, we verified that the column names were similar across the files. Once the column names were standardized, we could enter the data from the files into the table using a large commit function.
Processes
Schema
After becoming familiar with the dataset for each state, we identified the shared values between all files. We then used this information to create the database schema. We iterated several versions of the schema based on the needs of our project leads. In our finalized schema, we had a primary table with the Self-Sufficiency Standard information consistent across all files and four secondary tables with additional SSS information only present in some files. We also created tables to tie external data (e.g., from the Census and HUD) to the SSS data based on common analyses by stakeholders. We added boolean columns to the main table to indicate when the extra information was available. The primary keys are family type, state, place, year, and analysis type. The keys are the same across the main and helper tables to make it easy to link the data.
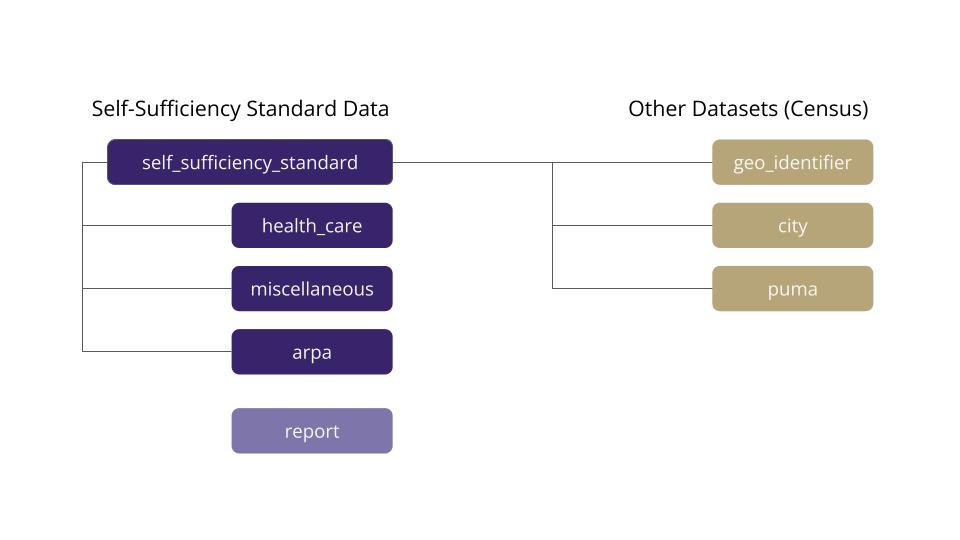
Figure 2: Database Schema
Coding the Database
We utilized the SQLAlchemy Python package to create the database tables and insert the data from the files into an SQLite database. After finalizing our schema, we broke into two teams to code the various tables via pair coding. During this workflow, we had the less experienced fellow type the code and the more experienced fellow assist them in writing it. After the work progressed, we transitioned into each team member working in their respective branch. We finalized the performance by creating functions to insert and extract the data from the database.