Point-in-Time
We created three different point-in-time household definitions. Our point-in-time definitions use only a single month of data. They start simple, incorporating just address information, and then increase in complexity, as we add last name information in two different ways.
Naive
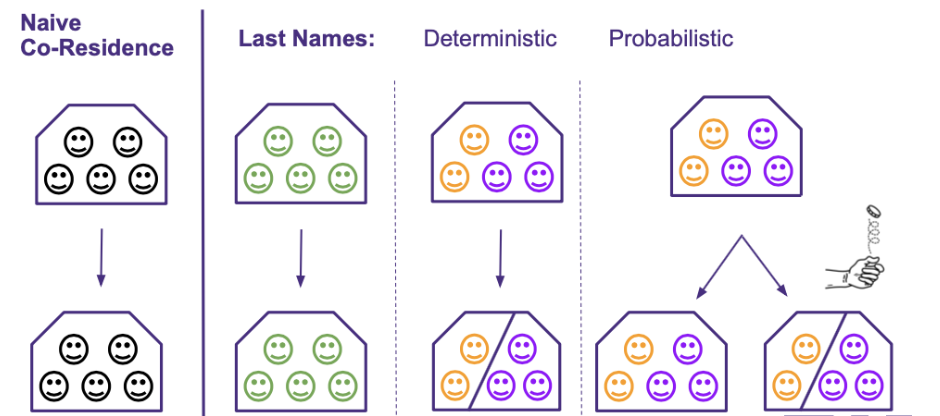
The naive coresidence definition groups the entire population by their imputed address for a given month. It takes the resulting residences, for example a house with five people shown in the diagram below, and labels them as households. In this definition, a household references people who live together at the same time.
The naive coresidence definition fails to capture whether or not these people are roommates, or family. We are more interested in the latter as we try to identify resource-sharing units for the purpose of measuring poverty.
Why Last Names?
Limited Options:
- No marriage licenses, minimal information on children
- Ethics of using demographics like race or sex to decide who is a household reinforces a heteronormative, racially homogenous traditional family
Pros of Last Names:
- If people live together and share a last name, they are almost certainly family
- We have one for almost everyone in the data
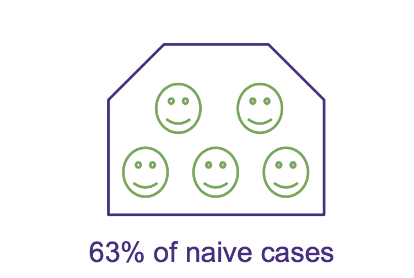
- 63% of naive households (including one-person households) have just one last name
- We can consider them a family and remove them from further exploration, so our dataset becomes smaller
 (color = last name)
(color = last name)
Last Names Deterministic
For the last name deterministic definition, we keep the naive definition for the residences where everyone shares a last name. When there are multiple last names, we split the residence into multiple households, one for each last name.
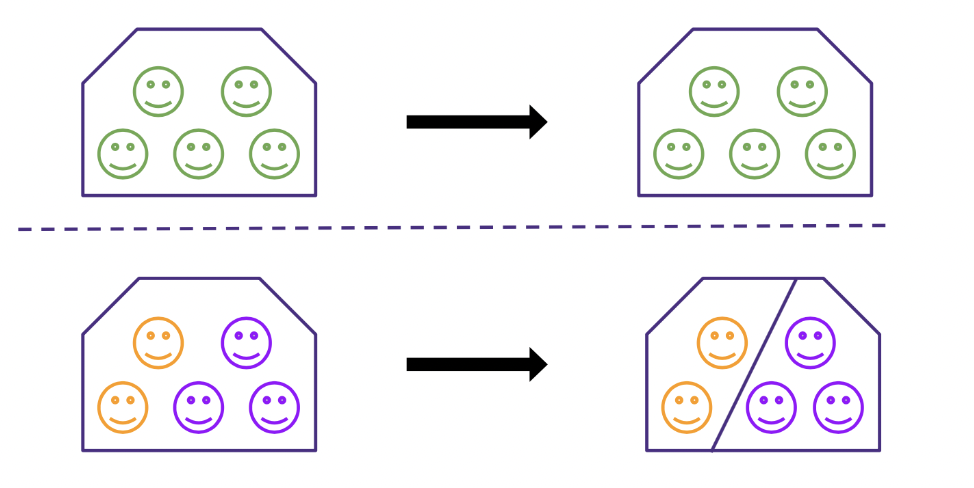 (color = last name)
(color = last name)
Last Names Probabilistic
Because we know that many families contain multiple last names, we try using a weighted coin for the residences with multiple last names to decide if we should keep the naive definition or split the people apart by last name.
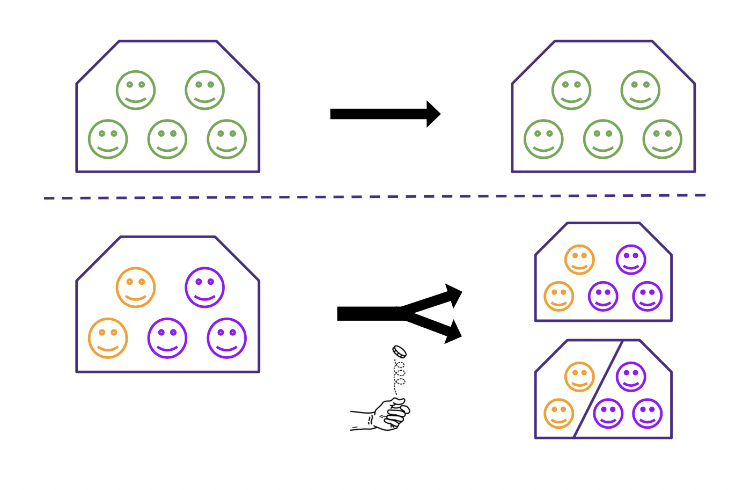 (color = last name)
(color = last name)
The coin is weighted by the likelihood that a residence is a family household according to Census data about household size and geographical tract. In the example below, two residences with the same household composition (five people, two last names) will have different probabilities since in County A, 80% of cases like this are families, compared to only 20% in County B.
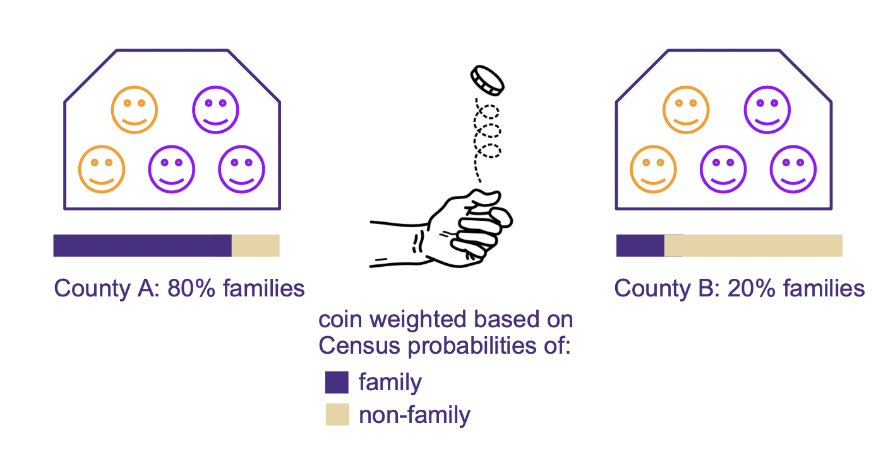 (color = last name)
(color = last name)