Methods
Data
WMLAD
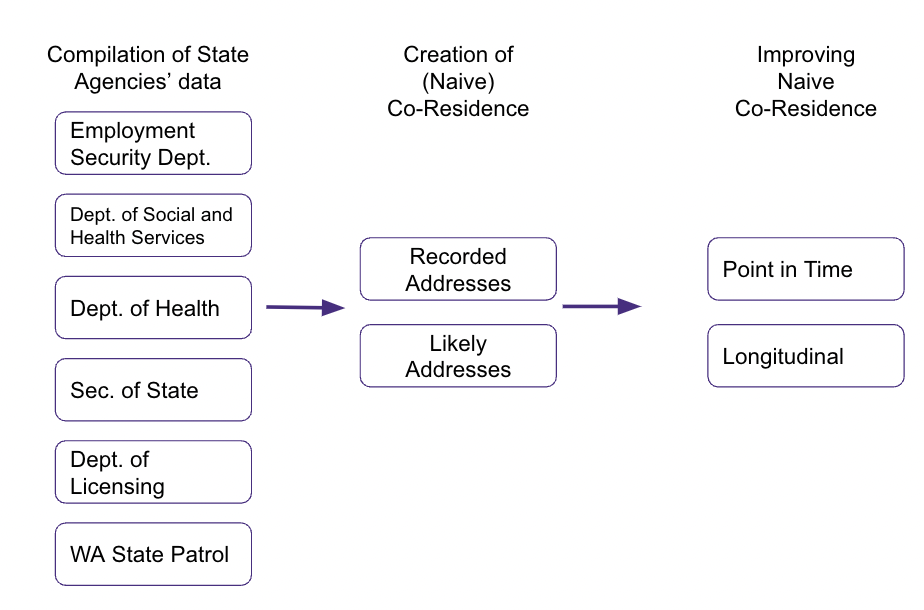
The Washington Merged Longitudinal Administrative Dataset (WMLAD) combines administrative data collected between 2010 and 2017 from several government agencies in the state, including the Employment Security Department (ESD), the Department of Social and Health Services (DSHS), Department of Health (DOH), Sec. of State, Department of Licensing (DOL), WA State Patrol. A few datasets that previous researchers formed out of the raw WMLAD data were also available. We were primarily interested in using information on addresses, demographics, and DSHS assistance units.
After the initial exploration of all of the available datasets, we built tables in a PostgreSQL database containing only the data we were interested in. We restructured the tables into the most convenient formats for storage and identified clear links between their variables. Additionally, we uploaded the 2010 Decennial Census data for the state of Washington to the database and linked with WMLAD geographies. Finally, we represented our database schema through an Entity-Relationship diagram that will help onboard future users of the data to quickly join tables or switch between wide and long formats.
Tools
The biggest concern when working with WMLAD is security, as it contains private information on individuals. Thus, all of the data analysis was completed on a secure data enclave without internet access, hosted by Center for Studies in Demography and Ecology (CSDE) at University of Washington. Within the enclave, R Studio and SQL were used to analyze the datasets. A local PostgreSQL database was created to speed up our workflow.
Software
- We mainly used programming in R through RStudio to connect to the PostgreSQL database, analyze data, and create and visualize results. We relied heavily on tidyverse packages, especially haven, dplyr and dbplyr, ggplot2, and tidycensus. Additionally, we used SQL to create and query a PostgreSQL database in order to access large data tables faster and more efficiently.
Interoperability
- Through the R tidverse package dbplyr, we were able to write tidyverse code and have it translated into SQL queries to run on our database.
Processes
First, we read background materials about the data generating process of WMLAD and about different academic approaches to constructing households from administrative data. Then, we familiarized ourselves with the WMLAD data, checked data quality, and decided ways to resolve inconsistencies. This included looking at household composition over time to modify the imputed addresses calculated in prior work.
At the same time, we strategized about which data to employ in creating households, and which definitions to create. Within R Studio, we picked 6 anonymized tracts to roughly represent Washington State and create a smaller dataset. This allowed us to load data into memory in RStudio and easily experiment with household definition algorithms before scaling up to the entire population. After finalizing our analysis, we used SQL and dbplyr to apply the algorithms to the whole WMLAD data for two months, April 2010 for the best Census comparison, and November 2014 for the best WMLAD data quality.